
2019年1月23日ついに日本でもGoogle for jobsが解禁となりました!
Google for jobsを使えばユーザーの検索キーワードに合わせて自社の求人広告を無料掲載できます!何も知らないユーザーが見たら初めは戸惑うかもしれませんが、
うまく有効活用する事でユーザーへの露出を増やして行きましょう。
Google for jobs概要
Google for Jobsは、2017年6月にアメリカで発表された、Googleによる求人検索機能です。求人を探しているユーザーに対して、自社の求人を表示する事ができます。
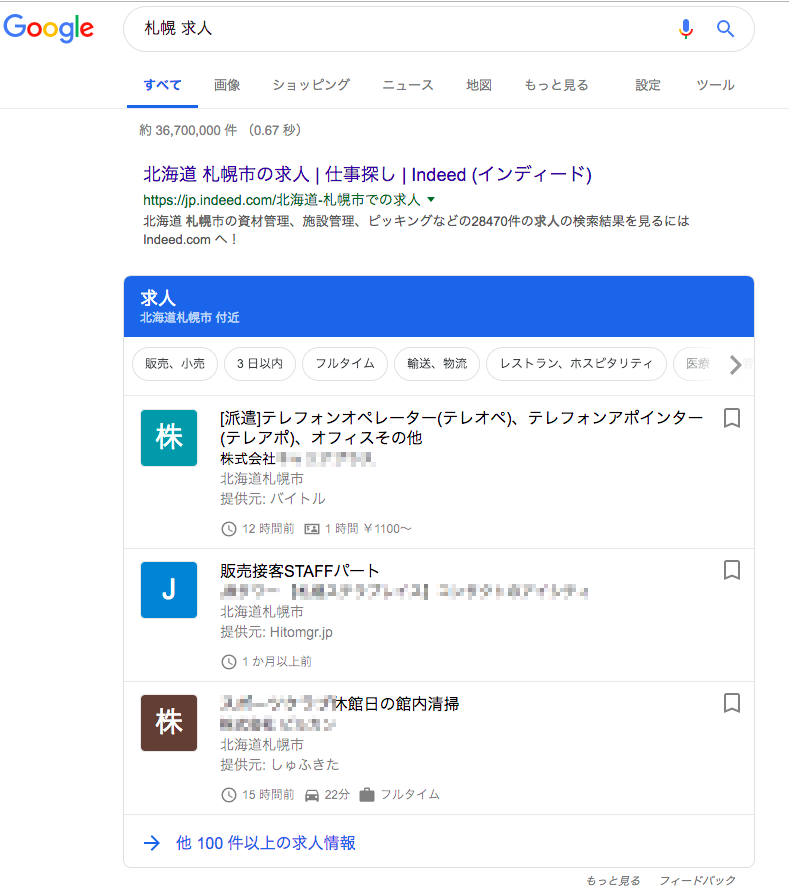
Google for Jobsは、求人情報サイトや企業の採用ページから求人情報を割り出し検索キーワードとマッチした求人を表示します。
作成方法
Google for jobsは求人情報サイトの登録していれば表示されることもありますが、自社サイトの求人ページからも配信できます。
Googleのヘルプページには作成は下記のように記されています。
- Googlebot が(robots.txt ファイルや robots メタタグで保護されていない)求人情報のウェブページをクロールできることを確認する。
- ホストの負荷の設定で頻繁なクロールが許容されていることを確認する。
- Google のガイドラインに準拠していることを確認する。
- 求人情報の構造化データをウェブページに追加します。
- 別の URL でホストされているサイトに同じ求人情報のコピーを掲載する場合は、ページの各コピーで正規 URL を使用します。
- 構造化データをテスト、プレビューします。
- 次のいずれかの操作を行い、Google に情報を提供し続けます。
Ⅰ.Indexing API を使用して、クロールする新しい URL や、URL のコンテンツが更新されたことを Google に通知します。
Ⅱ.Indexing API を使用しない場合は、GET リクエストを次の URL に送信して Google に新しいサイトマップを送信します。
サイト制作やそれらに携わっていない人は本当になんのことかわからないと思いますので、一つづつ解説していきます。
Googlebot が求人情報のウェブページをクロールできることを確認する。
はじめに、自社の求人ページがrobots.txt ファイルや robots メタタグを使用してクロール拒否していないか確認します。
クロールとは、検索エンジン内のシステムであるクローラがサイトを巡回し、サイトの情報を収集することを指します。
サイトがクロールされる事で、サーチエンジンにサイトが認識され、検索結果に表示されるようになります。
つまり、クロールを拒否しているページはサーチエンジンに認識されず、検索結果に表示されないという事です。
robots.txt ファイルの確認
robots.txt ファイルの確認は グーグルサーチコンソール内から行えます。
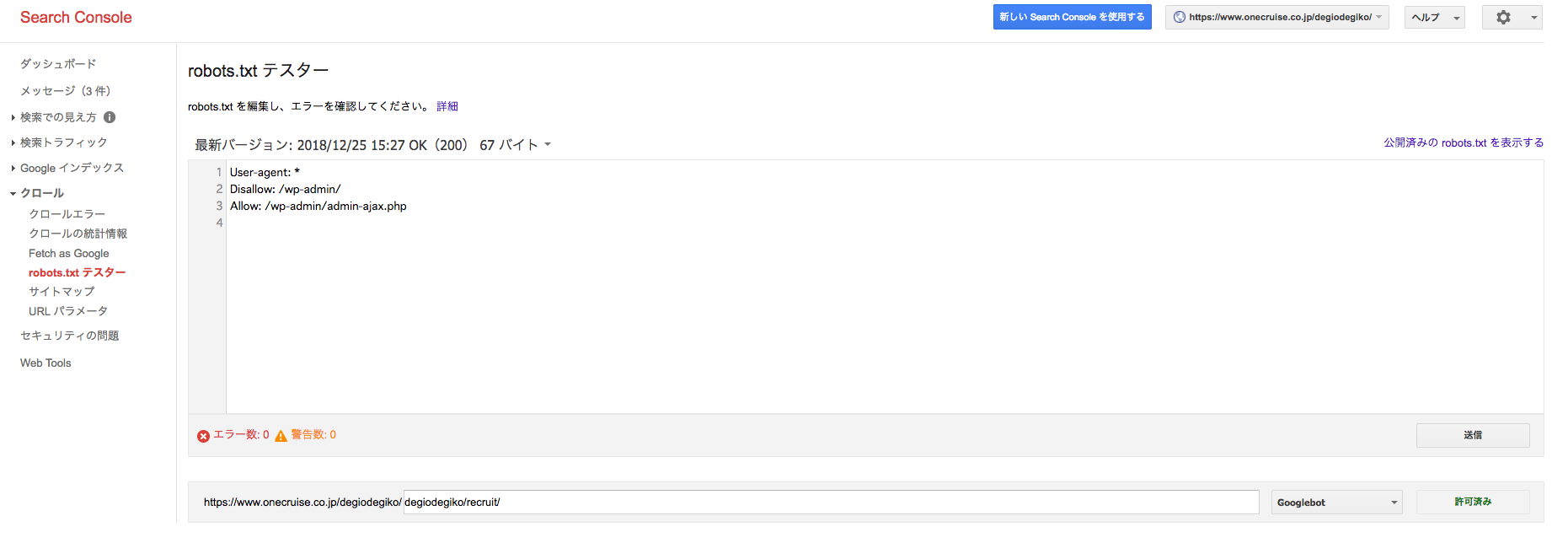
サーチコンソールの「クロール」項目から「robots.txtテスター」画面を開くと、ページ下部で指定したURLのクローリング可否状況を確認することができます。指定したURLがクローリングを許可しない設定にあると赤く表示されます。
robots メタタグの確認方法
自社の求人サイトから右クリックでページソースを表示します。

ソースの中からページ内検索でmeta nameと検索します。

meta nameが下記の3つでなければ問題ありません。
- 検索エンジンにインデックスさせない(noindex)
- 索エンジンにリンクをたどらせない(nofollow)
- インデックスとリンクの巡回をさせない(noindex,nofollow)
デジデジ採用サイトは
<name=”viewport” content=”width=device-width, initial-scale=1“>
となっておりますので問題ありません。
ホストの負荷の設定で頻繁なクロールが許容されていることを確認する。
クロール頻度とは、Googlebot がサイトのクロール時に行う 1 秒間あたりのリクエスト数のことであります。
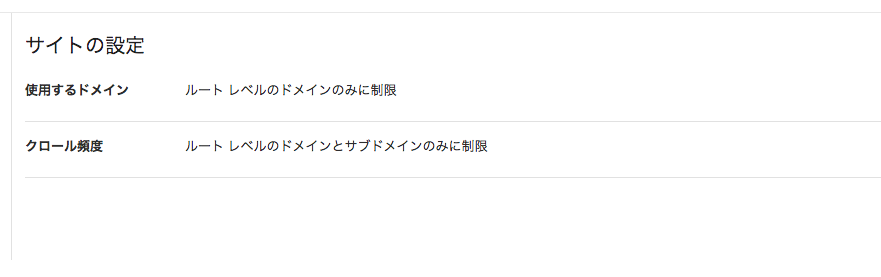
サーチコンソールの<歯車マーク>から<サイトの設定>を選択し、クロール頻度が制限されていないか確認します。
Google のガイドラインに準拠していることを確認する。
求人情報が Google の求人検索で表示されるようにするには、以下のガイドラインに準拠する必要がありますので、確認してください。
求人情報の構造化データをウェブページに追加します。
自社の求人情報を構造化データに書き込み、それを自社の求人ページに載せる事でGoogle for jobs に掲載する事ができます。
Googleのヘルプページにマークアップが掲載されていましたのでそちらを使って説明していきます。
<script type=”application/ld+json”> {
“@context” : “https://schema.org/“,
“@type” : “JobPosting”,
“title” : “Software Engineer”,
“description” : “<p>Google aspires to be an organization that reflects the globally diverse audience that our products and technology serve. We believe that in addition to hiring the best talent, a diversity of perspectives, ideas and cultures leads to the creation of better products and services.</p>”,
“identifier”: {
“@type”: “PropertyValue”,
“name”: “MagsRUs Wheel Company”,
“value”: “1234567”
},
“datePosted” : “2017-01-18”,
“validThrough” : “2017-03-18T00:00”,
“employmentType” : “CONTRACTOR”,
“hiringOrganization” : {
“@type” : “Organization”,
“name” : “Google”,
“sameAs” : “http://www.google.com“,
“logo” : “http://www.example.com/images/logo.png”
},
“jobLocation”: {
“@type”: “Place”,
“address”: {
“@type”: “PostalAddress”,
“streetAddress”: “1600 Amphitheatre Pkwy”,
“addressLocality”: “, Mountain View”,
“addressRegion”: “CA”,
“postalCode”: “94043”,
“addressCountry”: “US”
}
},
“baseSalary”: {
“@type”: “MonetaryAmount”,
“currency”: “USD”,
“value”: {
“@type”: “QuantitativeValue”,
“value”: 40.00,
“unitText”: “HOUR”
}
}
}
こちらのマークアップを自社の求人サイト用に編集して求人サイトページに載せます。このての作業をしたことはない人は見ただけで気持ち悪くなると思います。(笑)
一つ一つ分解して説明していきたいと思います!
“@context” : “https://schema.org/”,
“@type” : “JobPosting”,
こちらはいじらずにそのままにしてください
“title” : “Software Engineer”,
こちらは募集職業名を入力してください。たとえば、”WEBマーケター” のように指定します。
“description” : “Google aspires to be an organization that reflects the globally diverse audience that our products and technology serve. We believe that in addition to hiring the best talent, a diversity of perspectives, ideas and cultures leads to the creation of better products and services.”,
こちらは “title” で決めた職業の詳細や会社説明などを記入してください。
“identifier”: {
“@type”: “PropertyValue”,
“name”: “MagsRUs Wheel Company”,
“value”: “1234567”
こちらはサードパーティーの求人サイトが求人の識別に使うものですので<name>と<value>の””の中は空白で問題ありません。↓
“identifier”: {
“@type”: “PropertyValue”,
“name”: “”,
“value”: “”
“datePosted” : “2017-01-18”,
こちらは求人情報を投稿した最初の日付 を入力します。
“validThrough” : “2017-03-18T00:00”,
こちらは求人に有効期限がある場合は入力してください。無い場合は空白(“”)で問題ありません。
・”employmentType” : “CONTRACTOR”,
こちらは雇用形態です。下記から一つ以上選択して入力してください。
• “FULL_TIME”
• “PART_TIME”
• “CONTRACTOR”
• “TEMPORARY”
• “INTERN”
• “VOLUNTEER”
• “PER_DIEM”
• “OTHER”
複数入れる場合は、
[“FULL_TIME”, “CONTRACTOR”]
などのように入力してください。
“hiringOrganization” : {
“@type” : “Organization”,
“name” : “Google”,
“sameAs” : “http://www.google.com”,
“logo” : “http://www.example.com/images/logo.png”
},
こちらは会社名を入力します。
nameが会社名・sameAsがサイトURLを入力します。
logoはサードパーティの求人サイトの場合、特定の組織について、その組織のナレッジグラフ カードに表示されているロゴ画像とは異なるロゴを指定できます。なので、自社サイトの場合空白(“”)でも問題ありません。
ワンクルーズで言えば
『”name” : “ONE CRUISE”,
“sameAs” : “https://www.onecruise.co.jp/”,
“logo” : “https://www.onecruise.co.jp/wp-content/themes/onecruise_2017/assets/img/home__company__logo.png”』
と、入力いたします。
“jobLocation”: {
“@type”: “Place”,
“address”: {
“@type”: “PostalAddress”,
“streetAddress”: “1600 Amphitheatre Pkwy”,
“addressLocality”: “, Mountain View”,
“addressRegion”: “CA”,
“postalCode”: “94043”,
“addressCountry”: “US”
}
},
こちらは職場の情報を入力いたします。ワンクルーズであれば
“jobLocation”: {
“@type”: “Place”,
“address”: {
“@type”: “PostalAddress”,
“streetAddress”: “中央区大通西11丁目4番地 大通藤井ビル10F”, ←市町村以下の住所
“addressLocality”: “, 札幌市”, ←市町村
“addressRegion”: “北海道”, ←都道府県
“postalCode”: “0600042”, ←郵便番号
“addressCountry”: “日本” ←国
}
},
と入力いたします。
“baseSalary”: {
“@type”: “MonetaryAmount”,
“currency”: “USD”,
“value”: {
“@type”: “QuantitativeValue”,
“value”: 40.00,
“unitText”: “HOUR”
}
}
}
こちらは基本給を入力します。
給与の範囲を指定する場合は、value ではなく、minValue と maxValue を定義します。
ワンクルーズの場合、
“baseSalary”: {
“@type”: “MonetaryAmount”,
“currency”: “JPN”,
“value”: {
“@type”: “QuantitativeValue”,
“minValue”: 400000,
“unitText”: “YEAR”
}
}
}
このような数値になります。
これにて構造化データの作成は完了です!
別の URL でホストされているサイトに同じ求人情報のコピーを掲載する場合は、ページの各コピーで正規 URL を使用します。
求人ページが、複数の URL で同じページにアクセスできる場合や、ページにモバイル版と PC 版の両方がある場合などの、類似ページが複数ある場合、 Google に重複と見なされます。これらの URL の 1 つが「正規」版として選択されてクロールされ、その他の URL はすべて「重複」URL と見なされてクロールの頻度が減ります。
このような正規 URL を明確に指定しないと、Google によって URL が選択されるか、いずれの URL も同等の重要性を持つものと見なされることになります。そのため、下記の「正規 URL の指定が重要な理由」で説明するような望ましくない動作につながることがあり
構造化データをテスト、プレビューします。
先ほど作成した構造化データが間違っていないか(エラーを出していないか)確認します。
テストツールがありますので、そちらにコピペしてプレビューします。
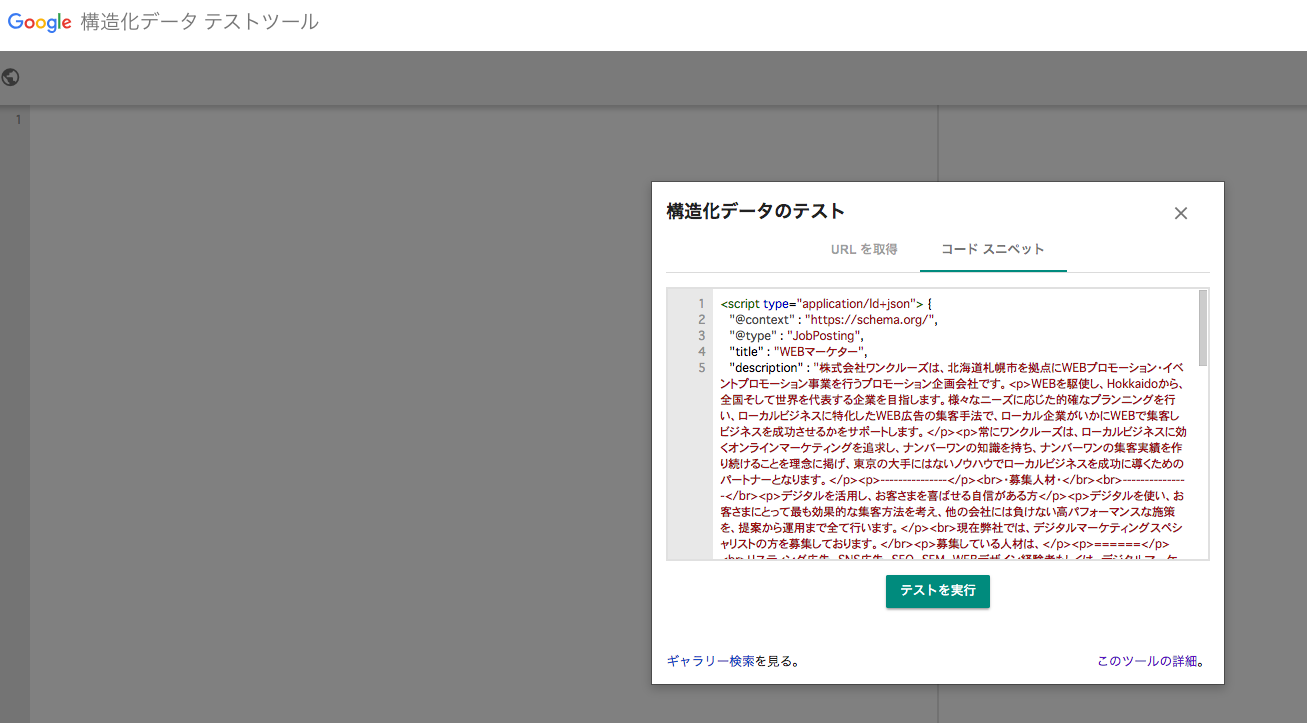
先ほど作った構造化データをコードスニペッドをコピペ(もしくはURL)、テストを実行します。
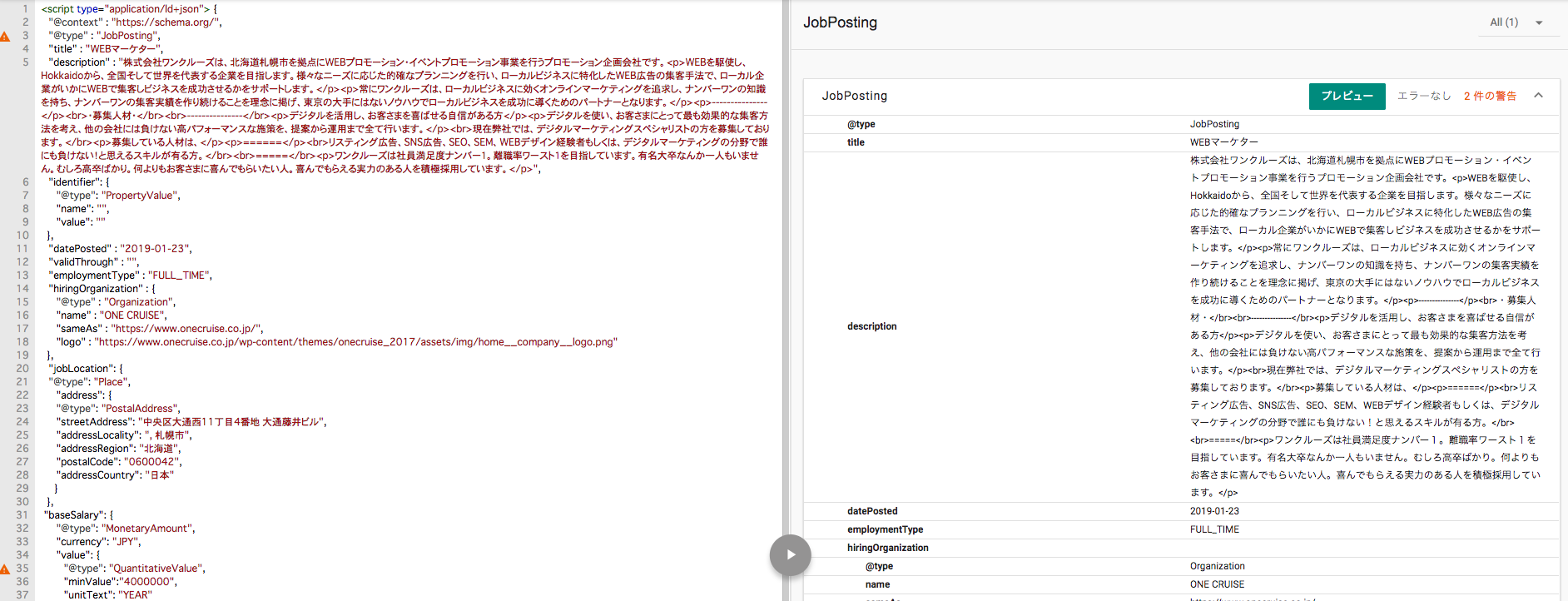
求人の期限などを空白にしていると警告サインが出ますが、エラーが出ていない限り問題ありません。
プレビュー画面↓
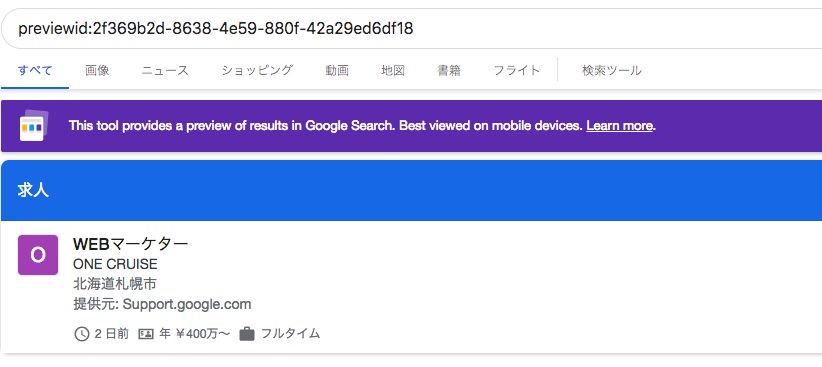
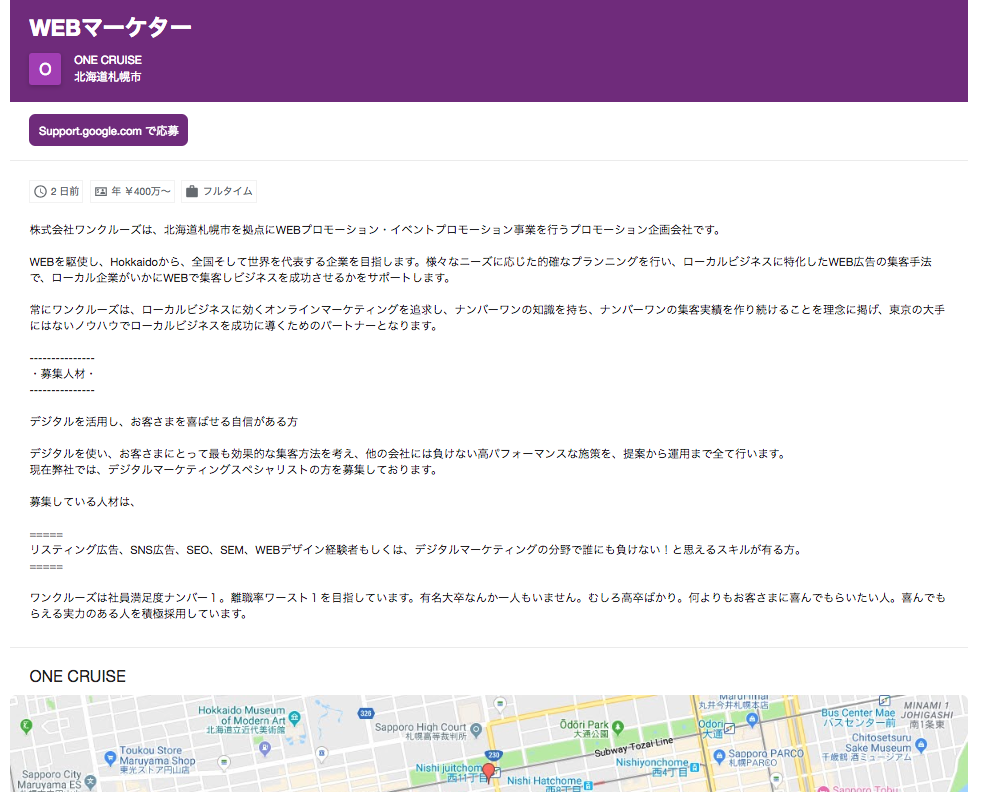
プレビュー画面で問題なく問題なく確認できましたら、求人詳細ページに入れてください。この作業は詳しい方でなければ難しいので、自社サイトを担当している制作会社に頼むのが良いと思います。
Google に情報を提供する
サイトに構造化データを載せた後、Googleに認知してもらう必要があります。記事の最初にも書きましたクロールをサーチコンソールで行います。
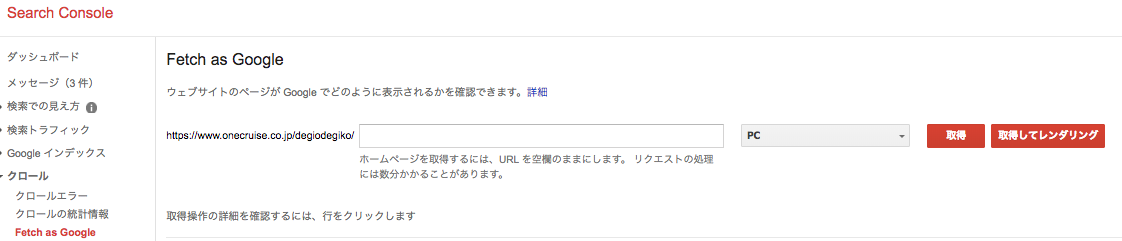
ダッシュボードの<クロール>から<Feich as Google>を選択します。構造化データを埋め込んだ求人ページのURLを入力して、現在「PC」となっているプルダウンを任意のものを指定してください。基本的にはPCとSPの2つで行います。あとは取得を押して完成です。
「取得」と「取得してレンダリング」の違いについて。
取得は単純にクローラにhtmlを読み込見ます。取得してレンダリングは取得したデータがどのように見えているかを確認する場合は選択します。
Googleへの情報提供(クロール)の方法ですが、ヘルプページでは、
『Indexing API を使用して、クロールする新しい URL や、URL のコンテンツが更新されたことを Google に通知します。
Indexing API を使用しない場合は、GET リクエストを次の URL に送信して Google に新しいサイトマップを送信します。
http://www.google.com/ping?sitemap=location_of_sitemap』
と記載されておりますが、こちらは基本的に、求人の数や、変更が多いサードパーティ向けの方法ですので、自社サイトで行う際はFeich as Googleで十分です。
まとめ
今回はGoogle for jobsの作成方法についてまとめました。一見難しそうに見えますが、案外なんとか出来ますのでぜひチャレンジして見てください!(それでも難しいのに変わりはありませんが笑)
他にも求人や集客にお困りでしたら、ぜひワンクルーズにお問い合わせください。お客様に喜んでいただける集客方法を提案させていただきます!


ワンクルーズのリスティング広告運用は、10万円/月(税別)から可能です。
10万円の中には、出稿費用・初期設定・バナー制作費・運用手数料まで全て含んでおりますので、乗り換え費用やアカウント構築費用等は一切かかりません!
ワンクルーズは、Google社から成功事例として紹介されただけでなく、
創業以来、契約継続率90%を維持しており、1,000を超えるアカウントの運用実績があります。
契約は1ヶ月単位で、期間の縛りは一切ございません。手数料の安さをうたう業者もあると思いますが、重要なのは費用対効果!
そこに見合う信頼できる業者をお探しなら迷わずワンクルーズへご相談ください!
おすすめの記事一覧
- 良い代理店か否かを見極める13個のポイント
- インスタグラム広告出稿におけるおすすめの媒体
- 中小企業がネット広告代理店を選ぶ時に比較すべき5つのポイント
- インターネット広告で効果が出ない時に見るべきチェックポイント














{kind=link}